Plant-focused mobile applications, like a plant app for sick plants free version, have developed rapidly over the last 15 years, moving from simple static databases to sophisticated, multi-functional platforms. Their history mirrors broader technological shifts in mobile computing, cloud services, and image recognition. Understanding this trajectory helps explain how these tools became indispensable to both casual gardeners and professionals.
Stage 1: Static Digital Encyclopedias (Late 2000s)
The earliest plant apps emerged when smartphones were just gaining popularity. These applications resembled digital pocket handbooks, offering:
Basic plant descriptions with a few images.
General care instructions (light, water, soil).
Simple categorization, often by plant family or alphabetical indexing.
From a software perspective, these were essentially offline databases, usually built with lightweight local storage to keep downloads manageable. Search capabilities were limited, and the user had to already know what plant they were dealing with.
Example workflow: The user typed “ficus,” scrolled through static text, and read a care entry. Interactivity was minimal.

Stage 2: Early Recognition Attempts (2010–2012)
The turning point came with widespread use of camera-equipped smartphones and access to faster internet connections. Developers began experimenting with recognition systems, often using rudimentary pattern-matching algorithms.
Features included:
Uploading photos to cloud servers for processing.
Comparing leaf shapes and colors against a database.
Community voting systems where users confirmed or corrected IDs.
From a programmer’s standpoint, these systems leaned heavily on template matching and color histograms rather than modern neural networks. Accuracy was inconsistent, but this marked the first attempt to reduce user dependency on prior knowledge.
Stage 3: Cloud-Backed Plant Identification (2013–2016)
As cloud infrastructure matured, plant apps began shifting most of their computation off-device. This allowed for larger datasets and faster iteration.
Advancements included:
Server-side image analysis, no longer limited by the phone’s hardware.
Growth of databases into the hundreds of thousands of plant species.
Integration with GPS metadata to filter results by region.
From the development side, these apps began adopting REST APIs for communication, delivering structured results back to the mobile client. Image compression, upload speed, and bandwidth management became critical engineering challenges.
Stage 4: Health Diagnosis and Problem Detection (2016–2019)
Once plant identification stabilized, developers turned their focus to diagnostics. This was more complex because symptoms could vary across lighting conditions, plant maturity, and environmental stress.
Key developments:
Recognition of fungal diseases (powdery mildew, rust, leaf spot).
Identification of pest damage (chewing marks, webbing, discoloration).
Detection of nutrient deficiencies through visual leaf patterns.
The engineering challenge was training recognition models on diverse image sets covering multiple stages of disease progression. Systems had to distinguish between, for example, nitrogen deficiency and early fungal infection — issues that look similar at a glance.
This era also saw user feedback loops introduced. Apps logged when users accepted or rejected a diagnosis, feeding this data back into model refinement.
Stage 5: Integrated Care Ecosystems (2020–Present)
Modern plant apps no longer stop at identification or diagnosis. They now offer ecosystem-level functionality, becoming full plant management platforms.
Typical features today include:
Plant libraries where users register all their plants.
Reminders and task scheduling for watering, pruning, fertilizing.
Sensors through phone hardware (light meters using lux readings from the camera, or water calculators factoring temperature and humidity).
Personalized recommendations based on region, season, and logged plant history.
From a technical perspective, apps rely on:
Large-scale cloud databases with continuous updates.
Image processing pipelines optimized for latency and accuracy.
Cross-platform development frameworks (React Native, Flutter) to serve both iOS and Android users.
Gamification and community modules, adding discussion boards, plant-sharing feeds, and progress tracking.
This integration marks the transformation of plant apps from simple utilities into multi-service platforms, blending education, diagnostics, and daily care.
Broader Trends in Evolution
Data Scale
Early apps: a few hundred entries stored locally.
Current apps: hundreds of thousands of species, millions of photos.
Accuracy
Early apps: frequent misidentification, heavily dependent on photo quality.
Current apps: recognition rates approaching professional-level identification for common species.
Connectivity
Early apps: designed to function offline with limited features.
Current apps: heavily dependent on cloud systems, but often offer offline logging and reminders.
User Experience
Early apps: static lists and clunky menus.
Current apps: streamlined, minimalistic interfaces optimized for real-time scanning and monitoring.
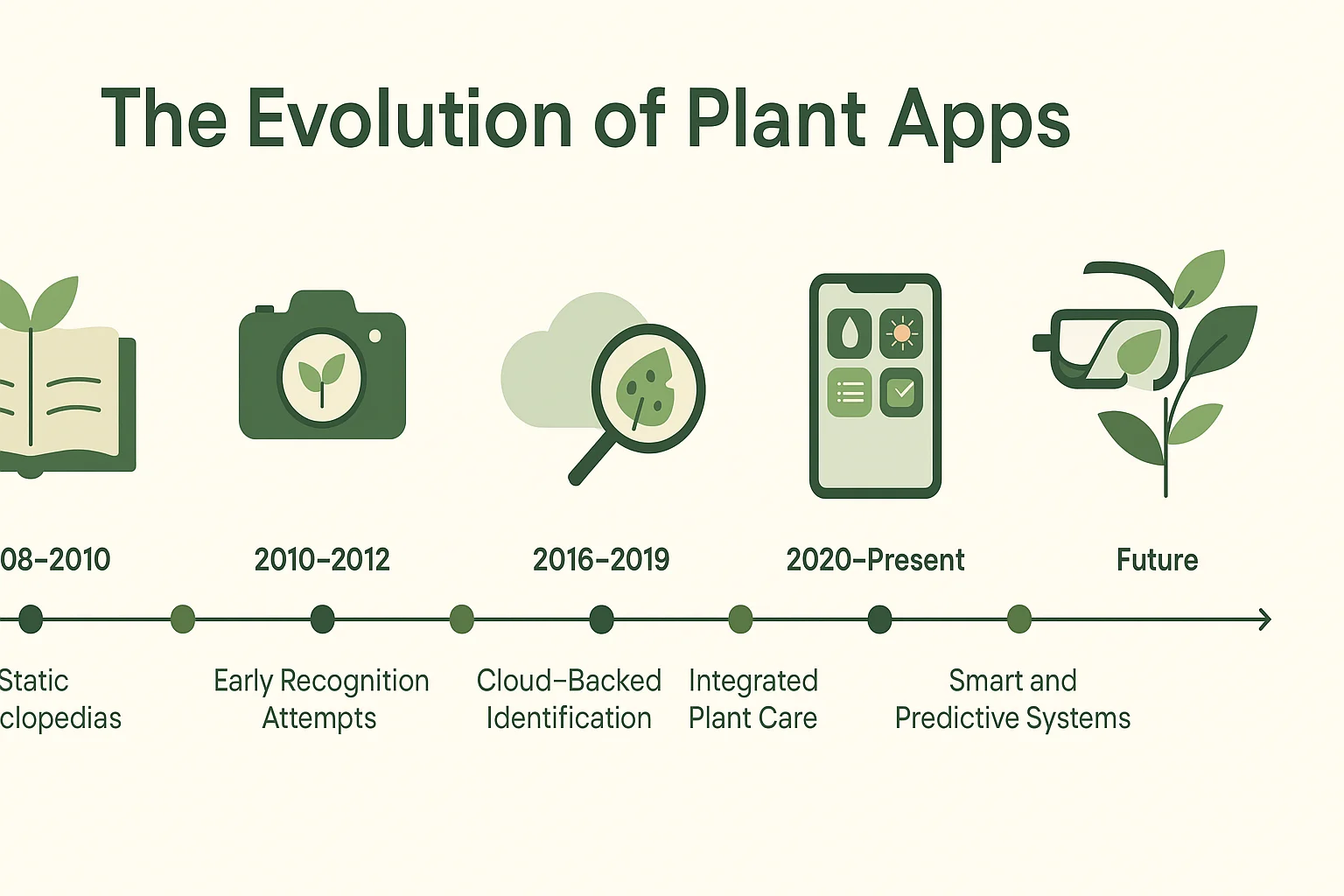
The Next Frontier
Looking forward, several paths for innovation are clear:
Deeper integration with hardware: pairing with smart pots, soil moisture sensors, or climate monitors.
Augmented reality overlays: using the camera to highlight which plant in a bed is under stress.
Predictive modeling: combining plant growth data with weather forecasts to anticipate problems before they appear.
Sustainability modules: providing ecological insights, such as pollinator support or invasive species warnings.
For developers, this will mean handling streaming data, ensuring low-latency responses, and building interfaces that remain simple despite complex back-end operations.
What began as a convenient reference has grown into a platform that supports observation, diagnosis, and long-term care.